Lab1 stream_reassembler 实现一个流重组器,一个将字节流的字串或者小段按照正确顺序来拼接回连续字节流的模块。
要求:
接收子串(由一串字节和大数据流中该串的第一个字节的索引组成),并提供一个ByteStream,其中所有的数据都被正确排序
注意考虑bytestream写满了的情况,以及reassembler满了的情况
注意边界等号
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof)会接收一个子串,用_output.write()将串整理后写入,同时bytestream中可能同时调用了read(),此时会改变边界。
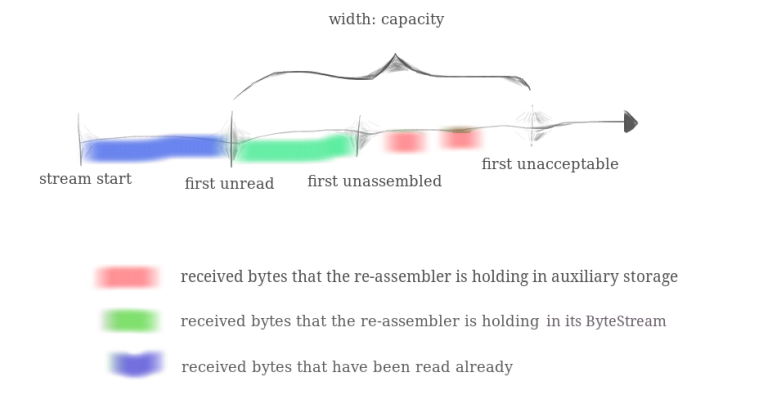
维护一个buffer list保证buffer不重叠,当data越界时需要裁剪。同时在write、插入buffer list时维护3个边界。
一开始我的想法是维护一个buffer的map,在插入新buffer时找到左侧已有的buffer判断是否重叠,如果重叠则合并两个buffer串,做相同的操作直到右侧(index+data.size()),同时还要维护整个map的capacity,并做裁剪。这样写出来的逻辑非常复杂。最后面向测试编程实在过不了所有测例,在最后折磨了一天后决定重写。
其实可以直接用capacity申请一个buffer的列表。没有字符的部分相当于字符\0,在插入子串时只需要计算出start和end的index,然后将buffer表的这一段覆盖即可,这样做就只需要维护unread,unassembled和unacceptable三个边界即可。在理解上和实现上都简化了太多!
tips:实在调不对代码时可以尝试检查前面lab的代码是不是真的写对了,比如把别人的代码copy过来如果还是过不了test。。。不然就会想我一样调了一天都调不对
stream_reassembler.hh
1 2 3 4 5 6 7 8 9 10 11 12 13 class StreamReassembler { private : std::deque<string> _buffer; std::deque<bool > _flag; bool _is_eof = false ; size_t _eof_idx = 0 ; size_t _unassembled_bytes_size = 0 ; ByteStream _output; size_t _capacity; ...
stream_reassembler.cc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 StreamReassembler::StreamReassembler (const size_t capacity) : _buffer(capacity, "" ), _flag(capacity, false ), _output(capacity), _capacity(capacity) {} void StreamReassembler::push_substring (const string &data, const size_t index, const bool eof) size_t _first_unassembled = _output.bytes_written (); size_t _first_unaccept = _first_unassembled + _capacity; if (index >= _first_unaccept || index + data.length () < _first_unassembled) { return ; } size_t begin_index = index; size_t end_index = index + data.length (); if (begin_index < _first_unassembled) { begin_index = _first_unassembled; } if (end_index >= _first_unaccept) { end_index = _first_unaccept; } for (size_t i = begin_index; i < end_index; i++) { if (!_flag[i - _first_unassembled]) { _buffer[i - _first_unassembled] = data[i - index]; _unassembled_bytes_size++; _flag[i - _first_unassembled] = true ; } } string wait_str; while (_flag.front ()) { wait_str += _buffer.front (); _buffer.pop_front (); _flag.pop_front (); _buffer.emplace_back ("" ); _flag.emplace_back (false ); } if (wait_str.length () > 0 ) { stream_out ().write (wait_str); _unassembled_bytes_size -= wait_str.length (); } if (eof) { _is_eof = true ; _eof_idx = end_index; } if (_is_eof && _eof_idx == _output.bytes_written ()) { _output.end_input (); } }