

前言
需要实现一个基于已有的敏感词库的敏感词过滤的功能
实现方案
遍历匹配
遍历词库的每一个词,匹配后进行过滤(比如把它们全部换成*号)
字符串匹配比较常见的算法有:
- Brute Force算法
- KMP算法
- Boyer-Moore算法(BM算法)
当然,用于字符串匹配的算法有非常多,这里不再赘述
一个敏感词库的词量往往是巨大的,它会远大于需要处理的文本量,在这种场景下使用遍历匹配的方法显然不可行
利用 DFA 算法
DFA:Deterministic Finite Automata (确定型有穷自动机)
从一个状态通过一系列的事件转换到另一个状态,即 state -> event -> state。
- 确定:状态以及引起状态转换的事件都是可确定的,不存在“意外”。
- 有穷:状态以及事件的数量都是可穷举的。
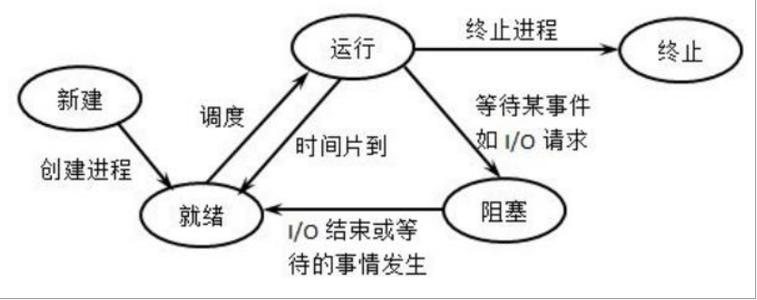
计算机操作系统中的进程状态与切换可以作为 DFA 算法的一种近似理解
举例:将DFA算法用于匹配关键词
我们可以将每个文本片段作为状态,例如“匹配关键词”可拆分为“匹”、“匹配”、“ 匹配关”、“匹配关键”和“匹配关键词”五个文本片段。

过程:
- 初始状态为空,当触发事件“匹”时转换到状态“匹”;
- 触发事件“配”,转换到状态“匹配”;
- 依次类推,直到转换为最后一个状态“匹配关键词”。
再让我们考虑多个关键词的情况,例如“匹配算法”、“匹)配关键词”以及“信息抽取”。
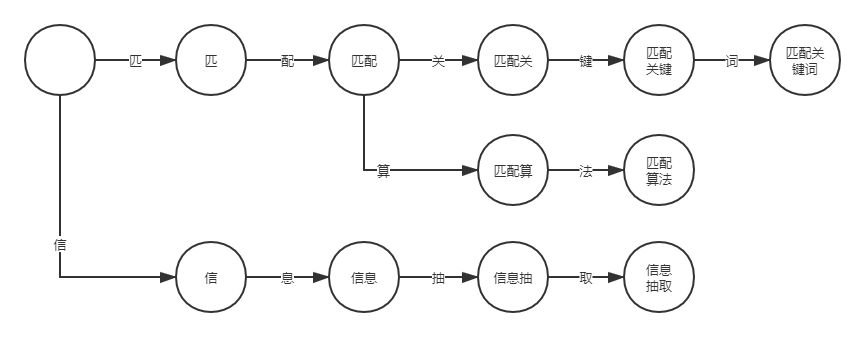
我们可以发现对于关键词匹配,它的状态是一个树形结构,这样我们判断一个词是否为敏感词时就大大减少了检索的匹配范围。
如何构建图示结构?
为了处理整个关键词库,我们可以使用字典(数组、哈希表、balabala…..)
字典使用 HashTable 实现,因为一个节点的子节点个数未知,而 HashTable 可以动态扩展,而且可以在 O(1) 的时间复杂度内判断某个子节点是否存在
1 | state_event_dict = { |
用嵌套字典来作为树形结构(这玩意就是Trie 树),key 作为事件,通过is_end字段来判断状态是否为最后一个状态,如果是最后一个状态,则停止状态转换,获取匹配的关键词。
每一个敏感词都可以看做一个关键词,构建敏感词的时间复杂度是可以忽略不计的,因为构建完成后我们是可以无数次使用的。对于查找敏感词的时间复杂度。如果字符串的长度为 n,而每个敏感词查找的时间复杂度是 O(m)(m 为最长的字符串的长度),我们需要对字符串遍历 n遍,所以查找敏感词的这个过程的时间复杂度为 O(m*n)。用DFA算法能够很好的满足需求。
缺点:占用的内存和敏感词库的大小成正比。
为什么不使用正则匹配
正则表达式引擎有两种:NFA和DFA。我们常常说用正则去匹配文本,这是NFA的思路。
大多数正则表达式引擎本质是NFA(非确定性有穷自动机)。而NFA由于在匹配时会多次回溯,导致相比于DFA效率低了很多
为什么正则使用NFA?:
NFA:Nondeterministic Final Auomaton(非确定型有穷自动机)
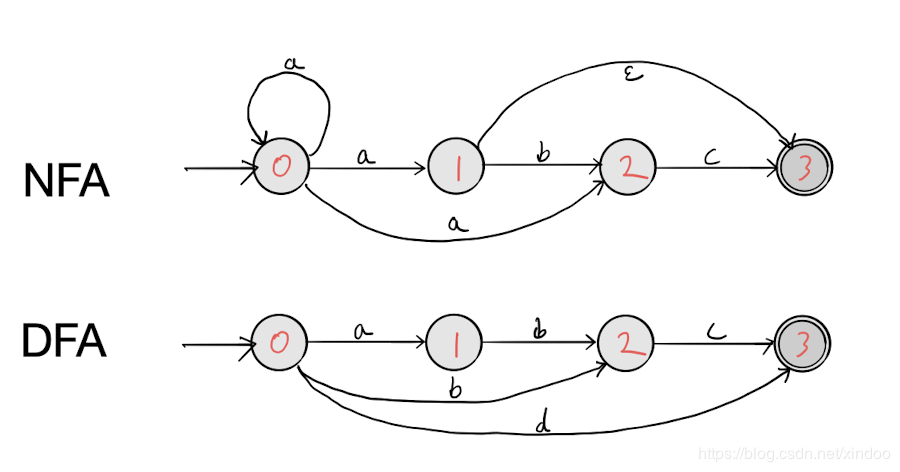
对于正则匹配,同样逐个读入待匹配字符,每读一个字符,即选取多种可能的匹配规则的一种继续匹配,一旦发现匹配失败,则回溯(backtrack)到之前的状态,重新开始尝试新的一种匹配,直至匹配完成
NFA vs DFA
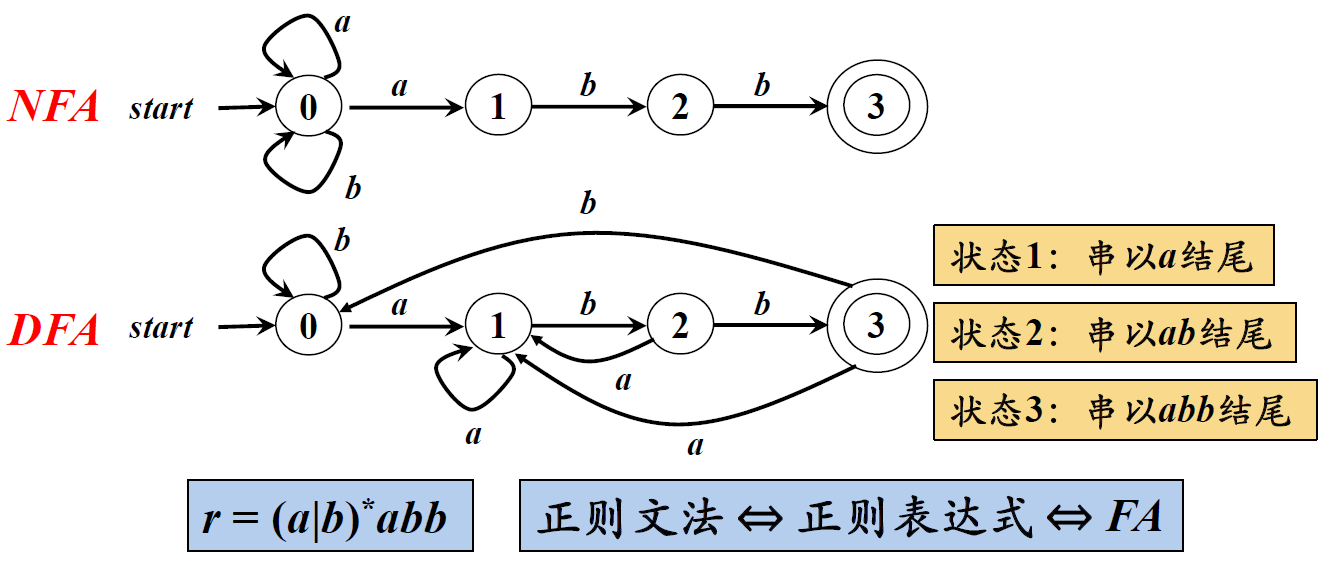
正则表达式在计算机看来只是一串符号,正则引擎首先肯定要解析它。NFA引擎只需要编译就好了;而DFA引擎则比较繁琐,编译完还不算,还要遍历出表达式中所有的可能。因为对DFA引擎来说机会只有一次,它必须得提前知道所有的可能,才能匹配出最优的结果
DFA的时间复杂度是线性的。DFA不记录所有可能的路径,结果是确定的。
NFA的时间复杂度较不稳定,好坏程度取决于正则表达式的书写与匹配对象的复杂程度。但NFA相较于DFA,它具有更强大的功能。因此,它也成为Java,JavaScript,PHP,Python,Ruby实现正则表达式的方式。NFA匹配结果,基于表达式,它记录所有可能的路径
正则中的非贪婪模式、反向引用、零宽断言等只有使用NFA引擎才有。因此大部分正则引擎都使用NFA来实现